CoCAtt contains driver attention data with distraction state captured by low-cost cameras and high-fidelty eye trackers in manual drive and autopilot setting.
Abstract
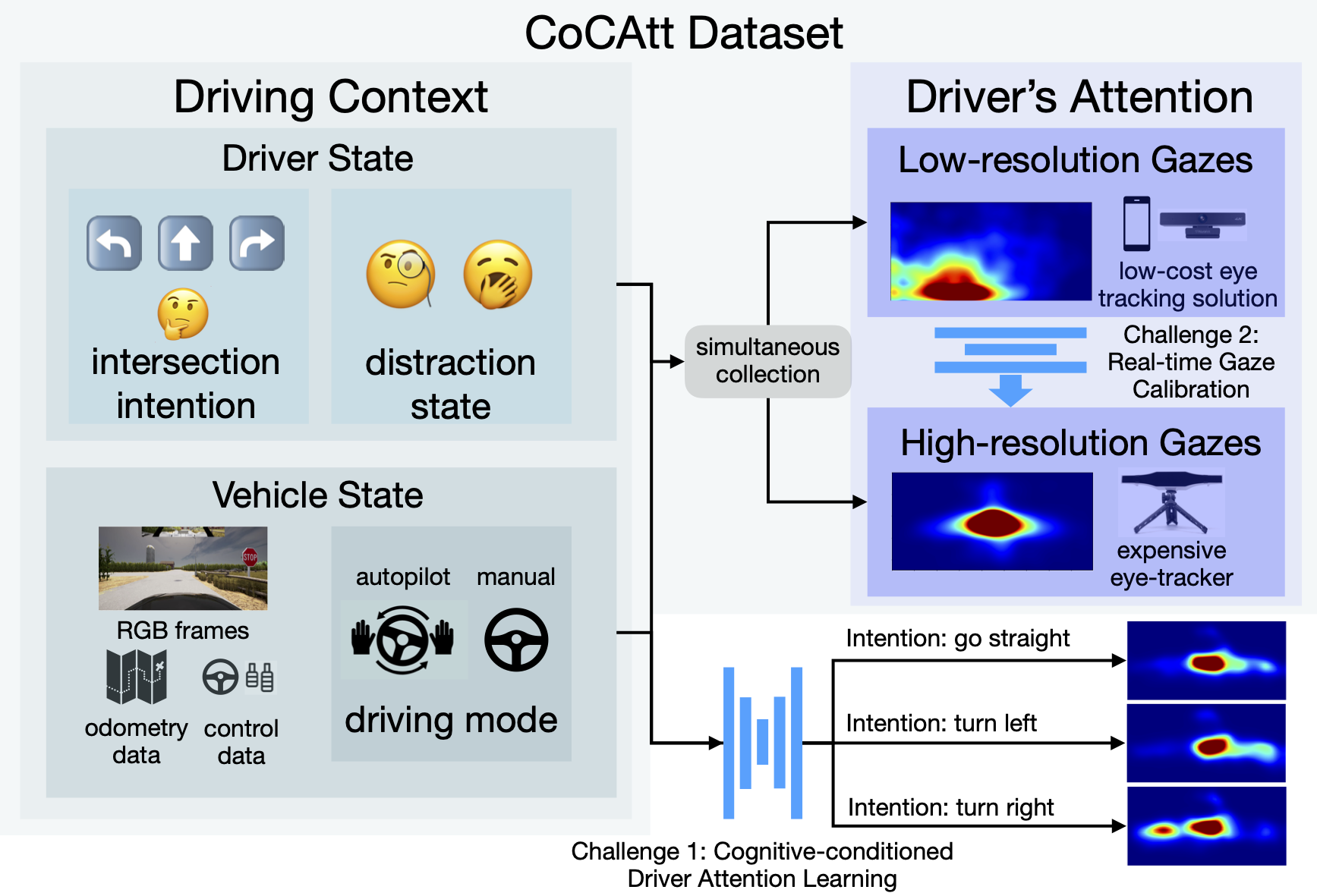
The task of driver attention prediction has drawn considerable interest among researchers in robotics and the autonomous vehicle industry. Driver attention prediction can play an instrumental role in mitigating and preventing high-risk events, like collisions and casualties. However, existing driver attention prediction models neglect the distraction state and intention of the driver, which can significantly influence how they observe their surroundings.
To address these issues, we present a new driver attention dataset, CoCAtt (Cognitive-Conditioned Attention). Unlike previous driver attention datasets, CoCAtt includes per-frame annotations that describe the distraction state and intention of the driver. In addition, the attention data in our dataset is captured in both manual and autopilot modes using eye-tracking devices of different resolutions. Our results demonstrate that incorporating the above two driver states into attention modeling can improve the performance of driver attention prediction.
To the best of our knowledge, this work is the first to provide autopilot attention data. Furthermore, CoCAtt is currently the largest and the most diverse driver attention dataset in terms of autonomy levels, eye tracker resolutions, and driving scenarios.
Hardware Setup and Software Interface

Dataset Folder Structure
Our dataset is grouped by participant ids. For each participant, we collect four sequences of manual drive attention data and two sequences of autopilot drive attention data. Along with driver attention heatmaps, CoCAtt contains RGB, depth and segmentation maps for each frame. To make it easier to parse, we provide one dataloader example script for PyTorch framework. The details of the dataset folder structure is as follows:
-[participant_id]/
---[autopilot/manual_drive]/
-----[sequence_id]/
-------video.mp4
-------final_labels.txt (contains per-timestamp information, including driver distraction state, car speed, acceleration, location, rotation, throttle, steer, brake, reverse gear, collision, lane_invasion)/
-------[images_4hz](RGB frames)/
-------[depths_4hz](depth frames)/
-------[seg_4hz](segmentation maps)/
-------[heatmap_4hz_20_eye_tracker](driver attention data collected by eye tracker)/
-------[heatmap_4hz_20_gaze_recorder](driver attention data collected by webcam)/
Note that we only use webcam device to collect manual-drive attention data. Besides, we only provide depth map in manual drive mode. Depth and segmentation maps are captured with the CARLA depth and Semantic Segmentation Sensor. Please checkout CARLA sensor documentation page for parsing.
Acknowledgment
This work was supported by State Farm and the Illinois Center for Autonomy. This work utilizes resources supported by the National Science Foundation’s Major Research Instrumentation program, grant #1725729, as well as the University of Illinois at UrbanaChampaign. We thank Zhe Huang for feedback on paper drafts.